オンプレ版は一生出ないだろうと思っていた23aiが、ただのRUを26aiにリネームするという斜め上の展開で登場したのが1月末。OCIやExadataのユーザはベータテスターかよ、というツッコミはさておき、同じようなやり口でGoldenGateも23aiから26aiにリネームされており、すでにGA版が利用できるようになっている。
Databaseは26aiがLTSということもあり、今後19cからの移行の話が増えると予想して、ちょっと触ってみたのでメモ。
実施環境
ソース側は Oracle Database 19c (19.28)。非CDBのシングルインスタンスでSIDは「ORCL」。接続には同名のデフォルトサービスを使用。移行は「TEST」というスキーマ単位で行う想定。
ターゲット側は Oracle AI Database 26ai (23.26.1)。CDBのシングルインスタンスでSIDは「ORCL」、PDBのサービス名は「ORCLPDB1」でこちらを接続に使用。
GoldenGateはソースでもターゲットでもない独立した中間サーバにインストールし、その上でExtractとReplicatを動作させる「Hub構成」とする。そのため、Distribution ServerやReceiver Serverの構築に関しては触れない。
中間サーバにGoldenGate 26aiをインストール
OSはOracle Linux 8。
マニュアルを見てもOSのパッケージ要件などについて明確に触れられておらず正確なところは不明だが、とりあえずDatabase用のPreinstallation RPMを導入しておく。
# dnf -y install oracle-ai-database-preinstall-26ai.x86_64自動的にoracleユーザが作成されるので適当にパスワードを設定。
# passwd oracle後は、ファイアウォールとSELinuxは手っ取り早く無効化して再起動しておく。
# systemctl stop firewalld
# systemctl disable firewalld
# sed -i -e "s/SELINUX=enforcing/SELINUX=disabled/" /etc/selinux/config
# systemctl rebootインストール先のディレクトリと、サービスマネージャ、ユーザデプロイメント用のディレクトリをそれぞれ作成。
# mkdir -p /u01/app/gg26/inst
# mkdir -p /u01/app/gg26/dp/sm
# mkdir -p /u01/app/gg26/dp/oracle_dp
# chown -R oracle:oinstall /u01/app
# chmod -R 755 /u01/appインストーラを展開。入手元は https://www.oracle.com/jp/middleware/technologies/goldengate-downloads.html
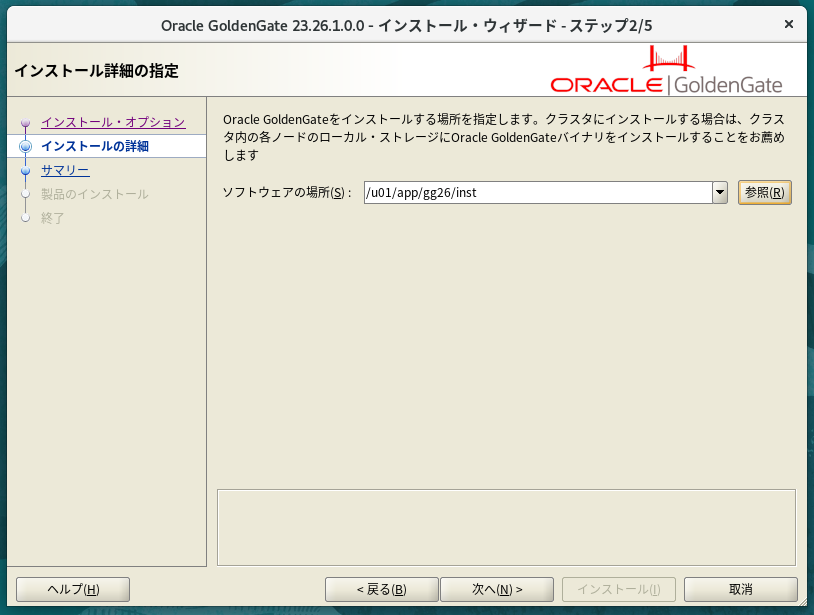
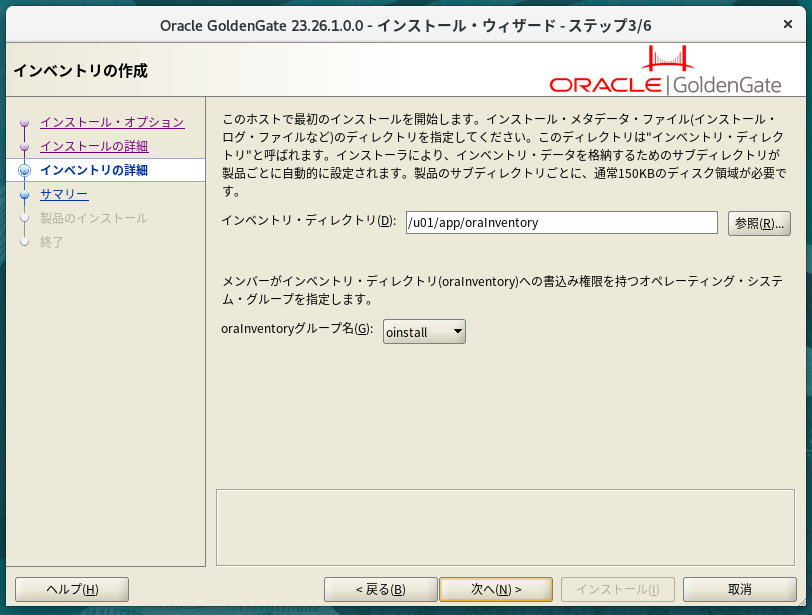
$ unzip -q /tmp/V1054774-01.zipインストーラを起動。
$ /tmp/fbo_ggs_Linux_x64_Oracle_services_shiphome/Disk1/runInstaller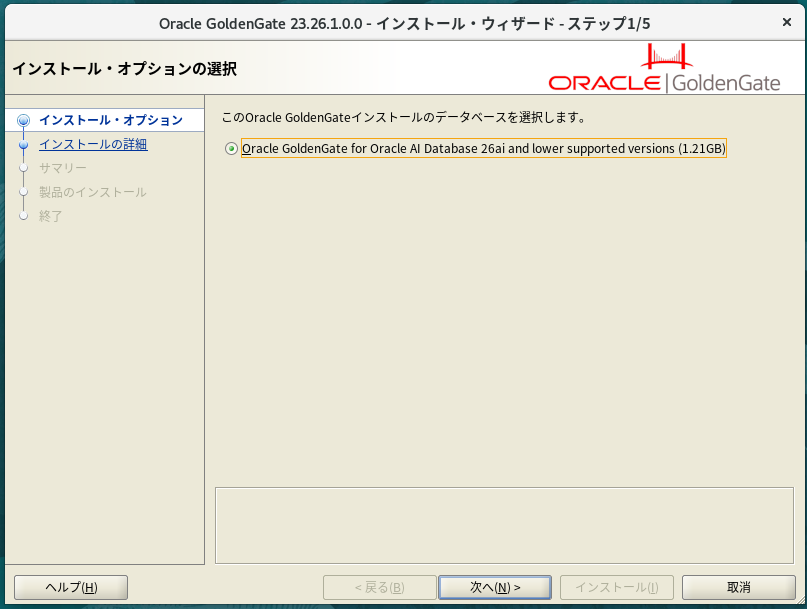
途中、rootでスクリプト実行を求められるのでその通りに実行する。
何事もなければ、特に詰まることもなく終わるはず。
中間サーバのOracle Client設定
26aiにはGoldenGateのバイナリの中にInstant Clientが同梱されている。ソースやターゲットへの接続には内部的にこのClientが使われるので、このタイミングでtnsnames.oraを設定しておく。
まずは設定ファイルの保存先ディレクトリを作成。
$ mkdir -p /u01/app/gg26/inst/lib/network/admintnsnames.ora を作成。ソースとターゲットそれぞれへの接続記述子を記載し、わかりやすい接続識別子を付けておく。ここではそれぞれシンプルに「source」、「target」とした。
$ cat <<"EOF" > /u01/app/gg26/inst/lib/network/admin/tnsnames.ora
source =
(DESCRIPTION = (ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = ol9db19.ex.home)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = orcl)))
target =
(DESCRIPTION = (ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = ol9db26.ex.home)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = orclpdb1)))
EOF各種環境変数を .bash_profile に設定して読み込んでおく。
$ cat <<"EOF" >> ~/.bash_profile
export TNS_ADMIN=/u01/app/gg26/inst/lib/network/admin
export PATH=$PATH:/u01/app/gg26/inst/lib/instantclient
export OGG_HOME=/u01/app/gg26/inst
export LD_LIBRARY_PATH=$OGG_HOME/lib:$OGG_HOME/lib/instantclient
export NLS_LANG=Japanese_Japan.AL32UTF8
EOF
. ~/.bash_profileここで、接続ができることも確認しておく。
[oracle@gg26aihub ~]$ sqlplus system/oracle@source
:
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
Version 19.28.0.0.0
に接続されました。
[oracle@gg26aihub ~]$ sqlplus system/oracle@target
:
Oracle AI Database 26ai Enterprise Edition Release 23.26.1.0.0 - Production
Version 23.26.1.0.0
に接続されました。デプロイメントの作成
中間サーバ上でサービスマネージャと、ユーザデプロイメントを作成する。
$ $OGG_HOME/bin/oggca.sh「サービス/システム・デーモンとして登録」にチェックを付けると、systemdのサービスユニットとして登録されOS起動時に自動起動してくれる。「ポート」は任意のポートを指定しておく。「セキュリティの有効化」のチェックを付けると管理コンソールでTLSを使用できるようになるようだが証明書の準備などが面倒なので今回は対応しない。
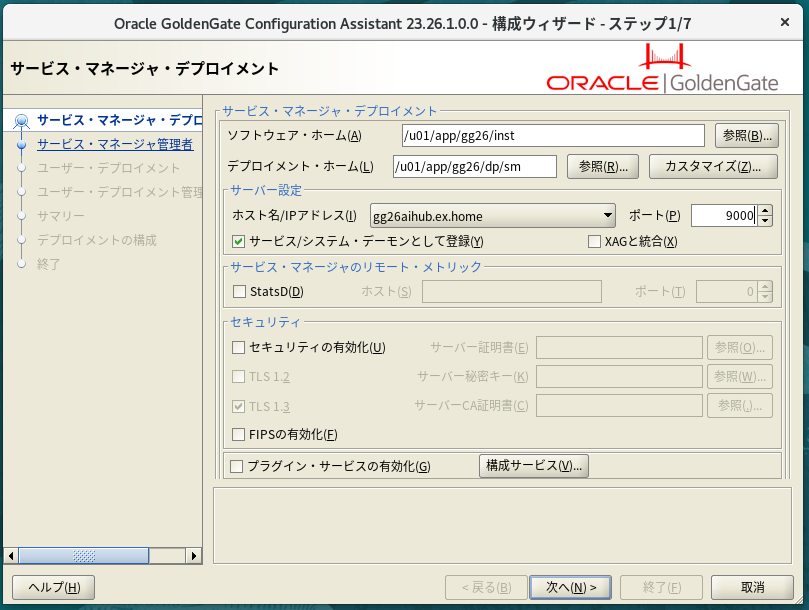
ここで指定するユーザ名・パスワードが管理コンソールへのログインアカウントになる。パスワードの設定が厄介なので「強力なパスワード・ポリシーの有効化」は外しておく。
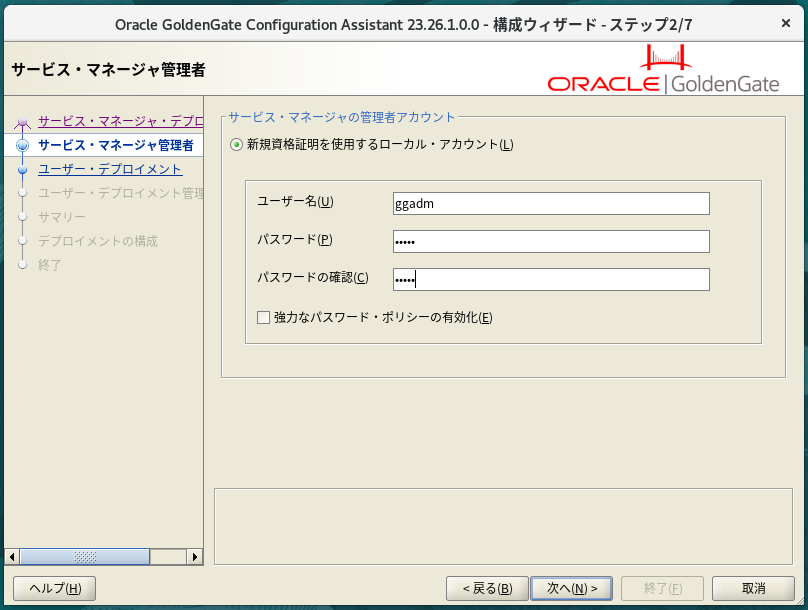
ユーザーデプロイメント側の「ポート」はサービスマネージャと連続したものが勝手に入るのでそのまま使っている。
「レプリケーション・スキーマ」には各データベースに作る管理ユーザと同じものを指定しているが、なぜここで指定しなければならないのかは謎(後で接続を作成するときにも個別に指定が必要)。
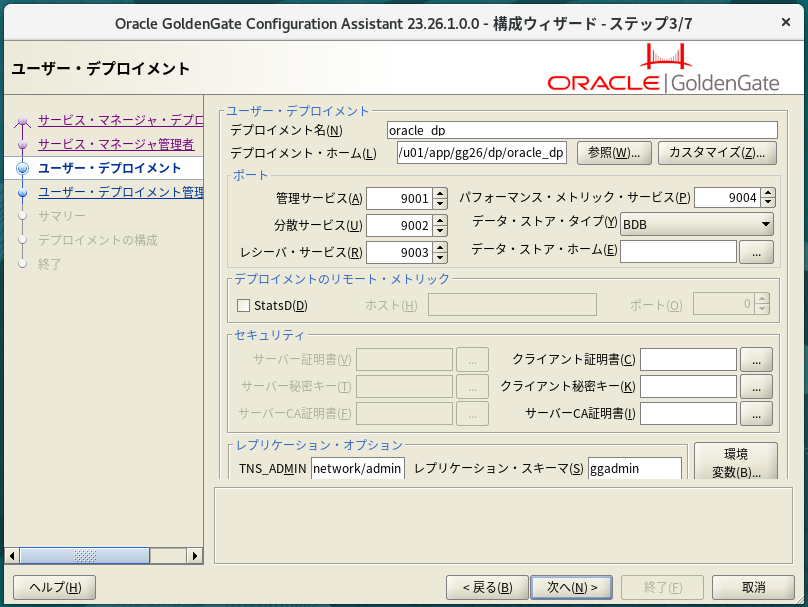
ユーザデプロイメントの管理者も、サービスマネージャと同じアカウントを指定しておく。
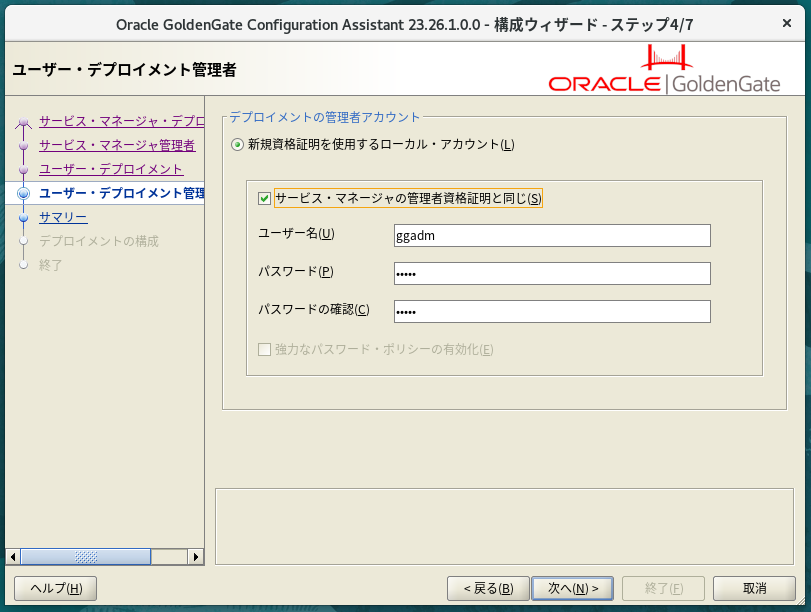
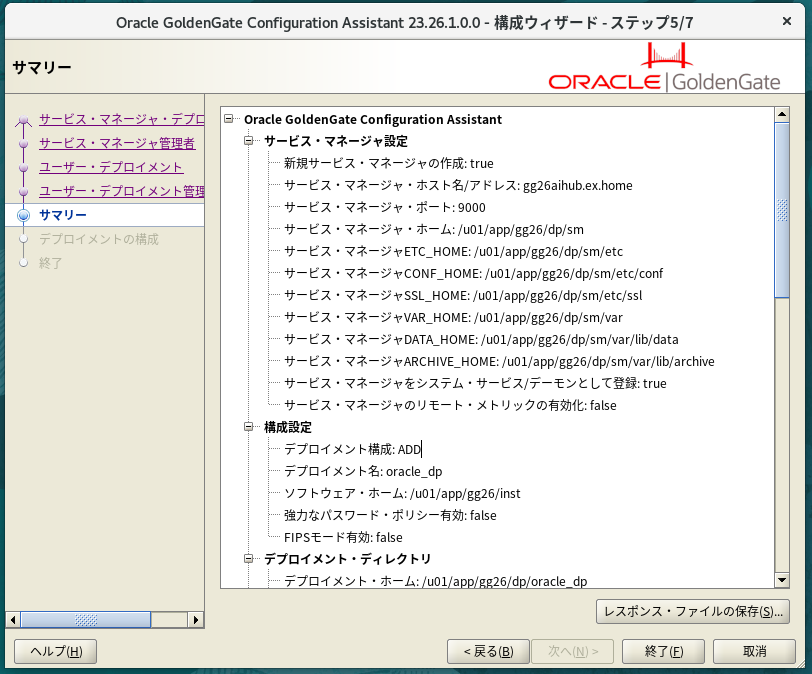
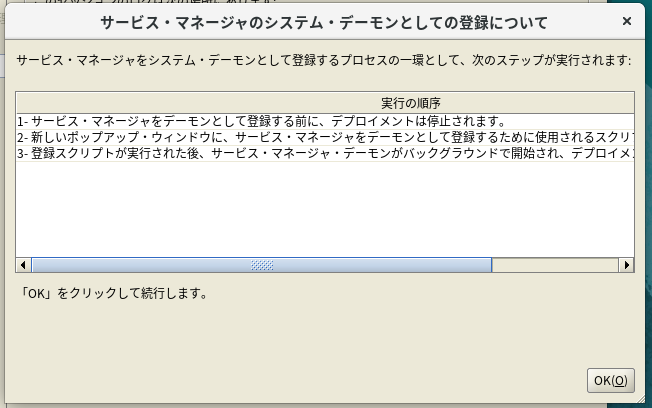
rootでのスクリプト実行を求められるので、指示通りに実行。
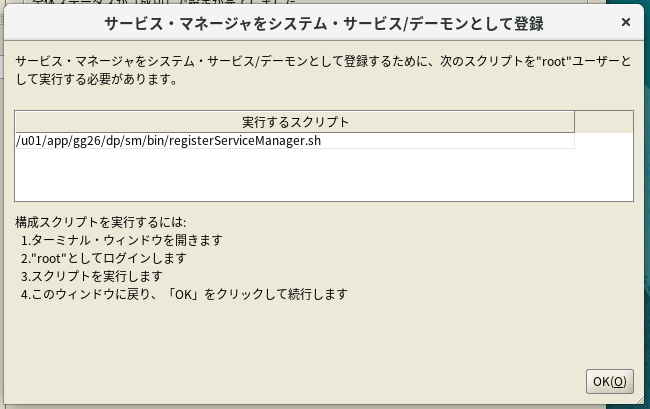
特に問題がなければ、デプロイメントの作成も完了。
ブラウザでサービスマネージャの管理コンソール画面が表示できることを確認する。

ソースデータベース側の準備
GoldenGateで移行できるようにデータベースの設定を変更する。
enable_goldengate_replication 初期化パラメータを設定。
alter system set enable_goldengate_replication=true;GoldenGate管理ユーザの作成。今回は 「ggadmin」というユーザを用いる。
create user ggadmin identified by ggadmin default tablespace users temporary tablespace temp quota unlimited on users;
grant dba to ggadmin;
exec dbms_goldengate_auth.grant_admin_privilege('ggadmin');アーカイブログモードになっていない場合はここで設定を変更。要再起動。
shu immediate
startup mount
alter database archivelog;
alter database open;最小サプリメンタルロギングと強制ロギングの設定。
alter database add supplemental log data subset database replication;
alter database force logging;
alter system switch logfile;初期移行用ダンプファイル配置ディレクトリの作成。
$ mkdir /home/oracle/dp_dircreate or replace directory DP_DIR as '/home/oracle/dp_dir';ここで移行対象のスキーマとデータも準備。
create user test identified by test;
grant create session, unlimited tablespace to test;
create table test.tab1(col1 number primary key, col2 varchar2(50));
insert into test.tab1 values(1, 'INITIAL DATA');
commit;ターゲットデータベース側の準備
こちらも、GoldenGateで移行できるようにデータベースの設定を変更する。
enable_goldengate_replication 初期化パラメータを設定。CDB単位で設定する。
alter system set enable_goldengate_replication=true;GoldenGate管理ユーザの作成。こちらも「ggadmin」というユーザを用いる。レプリケーション先PDBのローカルユーザとして作成する。
権限などの必要な設定は以下マニュアルに記載されているが、GRANT文が誤っておりそのまま実行することはできない(GRANT ALTER TABLE, GRANT DROP TABLE は仕様上エラーになる)。
alter session set container=orclpdb1;
create user ggadmin identified by ggadmin default tablespace users temporary tablespace temp quota unlimited on users;
GRANT CONNECT, RESOURCE to ggadmin;
GRANT OGG_APPLY, OGG_APPLY_PROCREP to ggadmin;
GRANT SELECT, INSERT, UPDATE, DELETE, ALTER on test.tab1 TO GGADMIN;
GRANT CREATE TABLE to ggadmin;初期移行用ダンプファイル配置ディレクトリの作成。
$ mkdir /home/oracle/dp_dirディレクトリオブジェクトもPDB内のオブジェクトとして作成する。
create or replace directory DP_DIR as '/home/oracle/dp_dir';ソースデータベースへの接続の追加
Webコンソール画面からユーザデプロイメントの管理サービス画面を開き、ソースデータベースへの接続を追加する。
「資格証明別名」は任意のものを指定。「ユーザID」にはソースデータベースに作成したGoldenGate管理ユーザ名とtnsnames.oraに記載した接続識別子の組み合わせを記載して作成する。
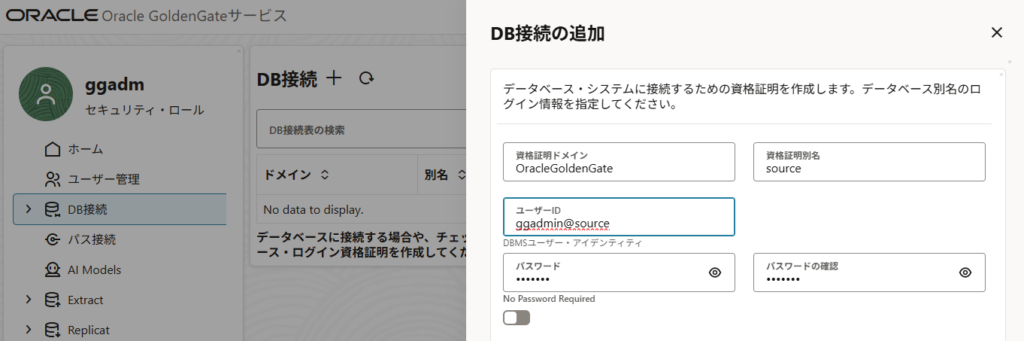
データベースへの接続ボタンを押下。
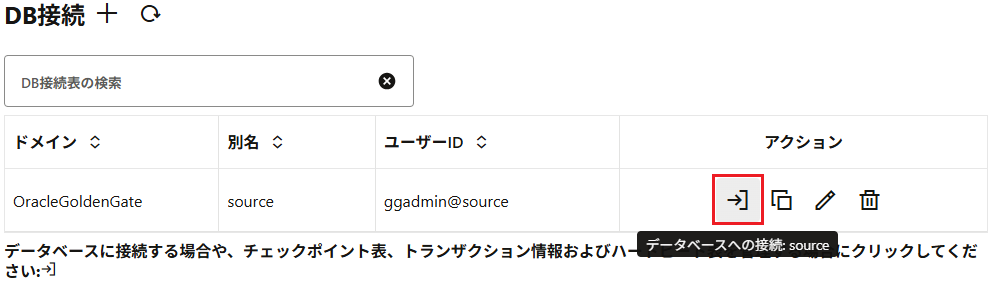
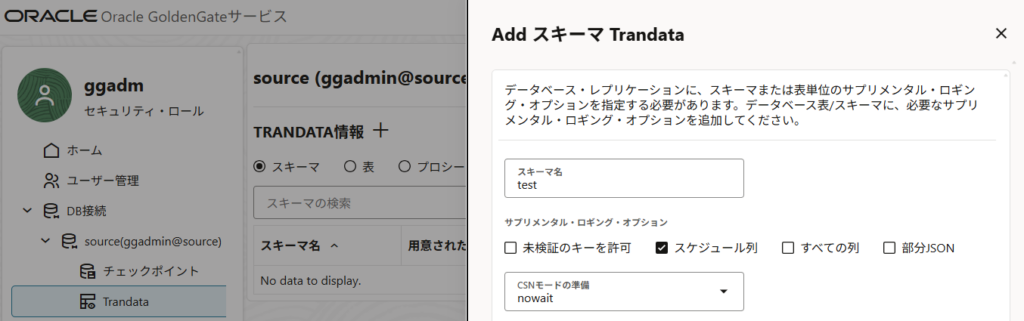
DB接続の一覧画面から対象の接続を展開して、「Trandata」を開き、TRANDATA情報を追加する。今回はスキーマ単位でサプリメンタルロギングを有効化する。「スキーマ名」に移行対象のスキーマを指定する。「CSNモードの準備」はデフォルトで「nowait」が選択されているが、これは初期移行時のデータ断面の取得にインスタンス化CSNを利用する設定なのでそのままにしておくこと。
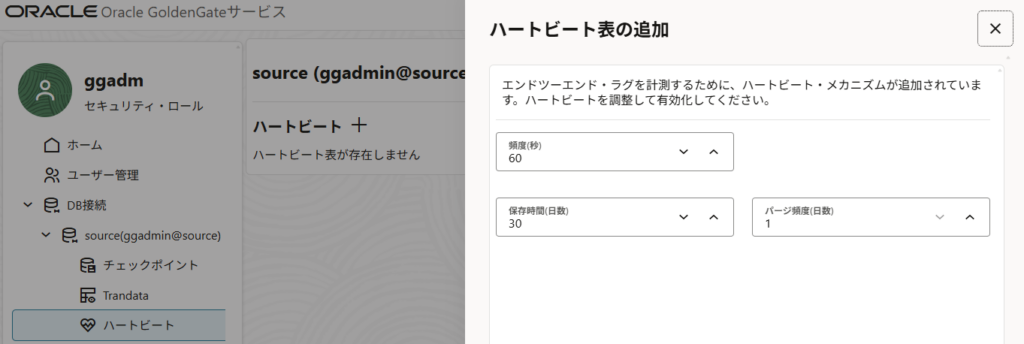
ハートビート表も追加しておく。設定はデフォルトのままで特に変更しない。
ターゲットデータベースへの接続の追加
ソースデータベースと同じように、ターゲットデータベースに対してもDB接続の追加を行う。
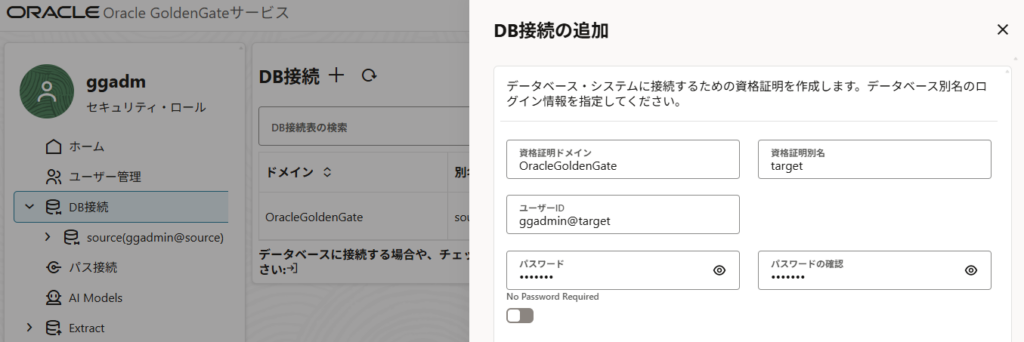
こちらも、データベースへの接続ボタンを押下。
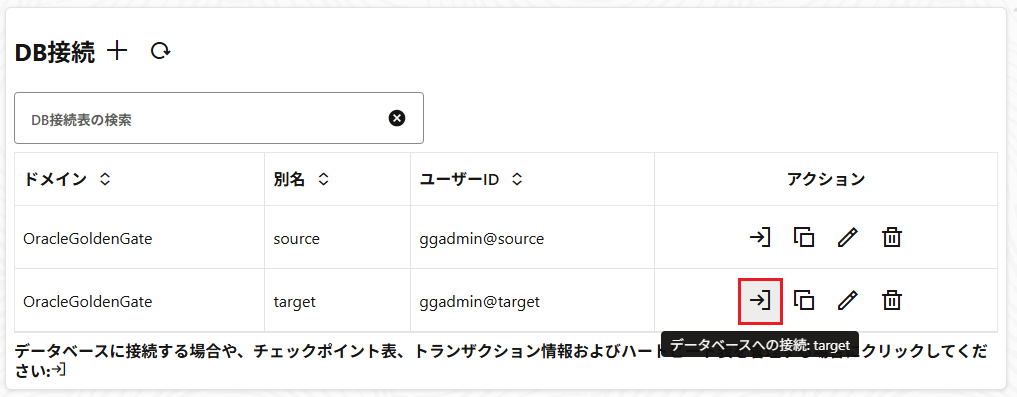
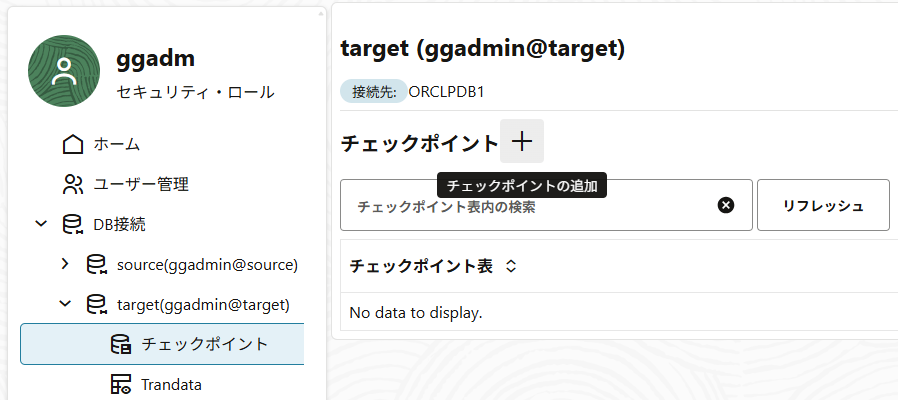
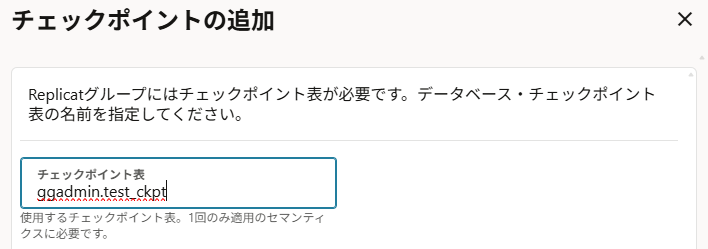
DB接続の一覧画面から対象の接続を展開して、「チェックポイント」を開き、チェックポイント表を追加する。
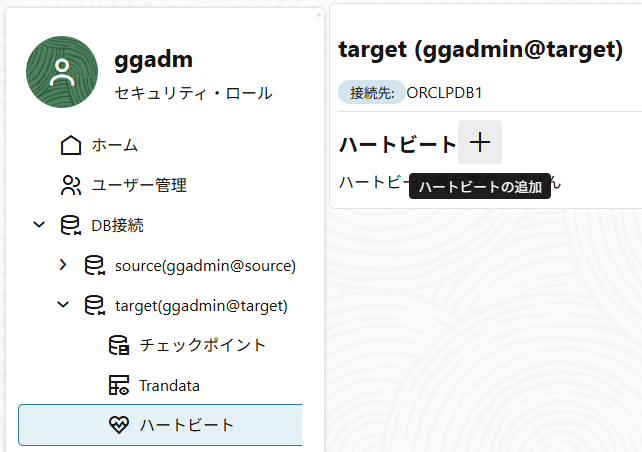
ハートビート表も追加しておく。設定はデフォルトのままで特に変更しない。
Extractプロセスの追加
「Extractの追加」ボタンを押下。
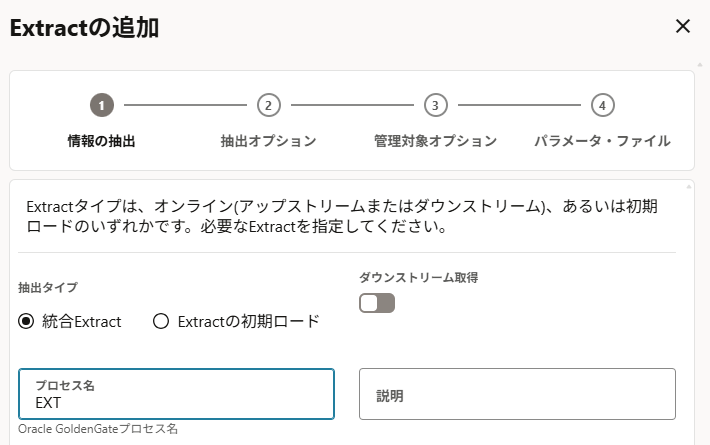
プロセス名は今回「EXT」としている。
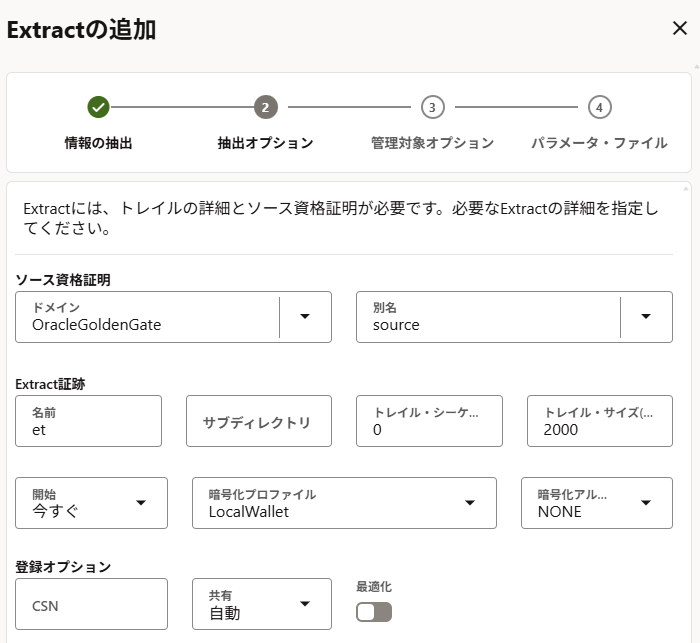
「ソース資格証明」や「別名」は作成済みのものを選択。「Extract証跡」には適当な2文字を指定。
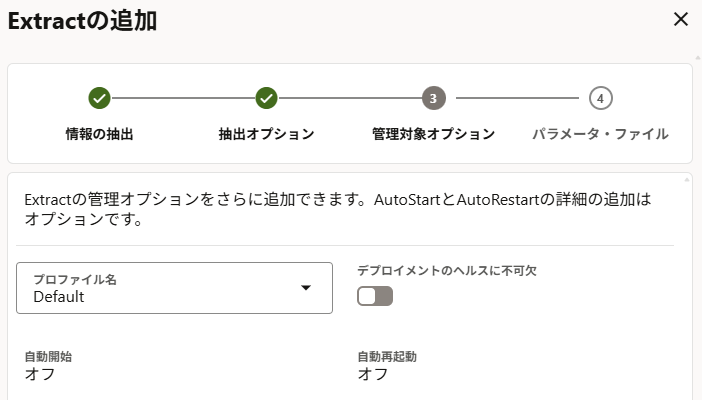
「パラメータ・ファイル」のテキストエリアに移行対象のテーブルを指定する。
ここで「作成および実行」を押下するとExtractプロセスが作成された後データの抽出も開始されてしまうので、先にReplicatプロセスの設定などを済ませておきたい場合は「作成」だけする。
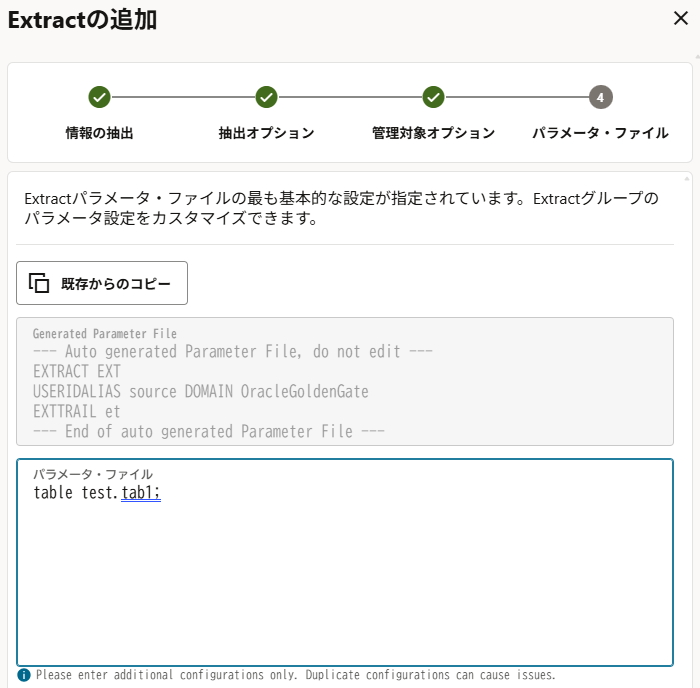
今回はテストなのでこの時点で「作成および実行」を押下して抽出も開始させている。
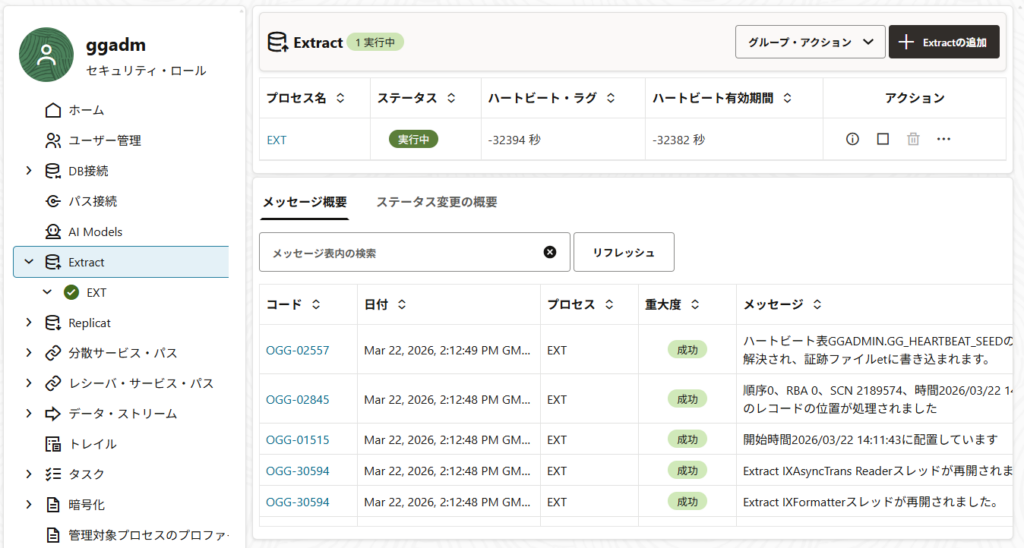
Extractプロセス開始 → Expdp実行前のデータ投入テスト
今回はデータの初期移行(ソースからターゲットへのDataPumpによるExpdp・Impdp)を行う前にExtractを開始し、変更データの抽出を開始している。つまり、Extractの起動からExpdpの実行までの間にソースに行われた処理はトレイルファイルとDataPumpのダンプファイルの両方に記録されており、何も考えずにターゲットへのImpdpとReplicatの起動を行うと、DML処理が重複してしまう。
この重複を自動的に解決するため、インスタンス化CSNという機能が使用できる。仕組みとしては、ソースの表をExpdpする際、その時点のSCNがダンプファイルに記録され、ダンプファイルをターゲットにImpdpすると、Replicatがそれ以降のSCNからデータを適用するという動き。
これを実際に確認するため、この状態で一度ソースの表にデータを投入しておく。
insert into test.tab1 values(2, 'POINT A');
commit;
SQL> select * from test.tab1;
COL1 COL2
---------- --------------------------------------------------
1 INITIAL DATA
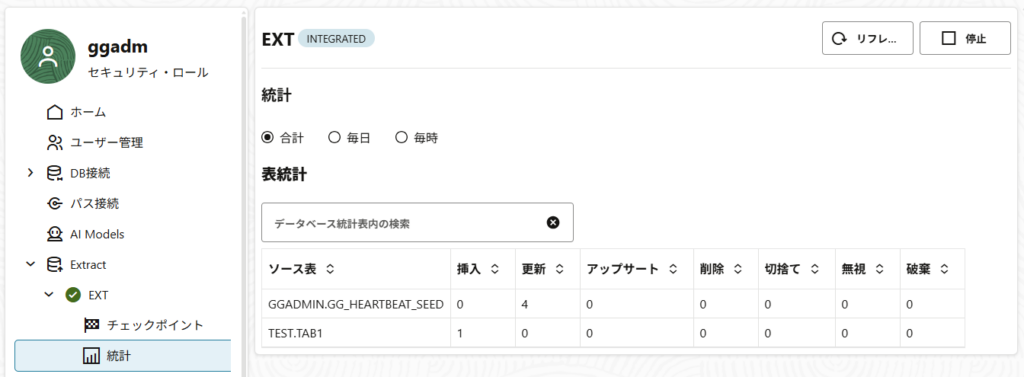
2 POINT A※ちなみに、Extractの統計を見てもこのINSERTが認識されていることがわかる。これはReplicatでは適用されず、一意制約違反(ORA-1)は発生しないのが想定される動作。
初期移行のためのExpdpを実行
ソースからDataPumpのExpdpでエクスポートを実行し、初期移行用のダンプファイルを生成する。
ちなみに、「FLASHBACKでは、データベース整合性が自動的に維持されます。」の一文がおそらくインスタンス化CSNの動作によるものと思われる。
[oracle@ol9db19 ~]$ expdp system/oracle directory=dp_dir schemas=test
Export: Release 19.0.0.0.0 - Production on 日 3月 22 14:19:27 2026
Version 19.28.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
接続先: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production
FLASHBACKでは、データベース整合性が自動的に維持されます。
SYSTEM."SYS_EXPORT_SCHEMA_01"を起動しています: system/******** directory=dp_dir schemas=test
オブジェクト型SCHEMA_EXPORT/TABLE/TABLE_DATAの処理中です
オブジェクト型SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICSの処理中です
オブジェクト型SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICSの処理中です
オブジェクト型SCHEMA_EXPORT/STATISTICS/MARKERの処理中です
オブジェクト型SCHEMA_EXPORT/USERの処理中です
オブジェクト型SCHEMA_EXPORT/SYSTEM_GRANTの処理中です
オブジェクト型SCHEMA_EXPORT/DEFAULT_ROLEの処理中です
オブジェクト型SCHEMA_EXPORT/PRE_SCHEMA/PROCACT_SCHEMAの処理中です
オブジェクト型SCHEMA_EXPORT/TABLE/PROCACT_INSTANCEの処理中です
オブジェクト型SCHEMA_EXPORT/TABLE/TABLEの処理中です
オブジェクト型SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINTの処理中です
. . "TEST"."TAB1" 5.5 KB 2行がエクスポートされました
マスター表"SYSTEM"."SYS_EXPORT_SCHEMA_01"は正常にロード/アンロードされました
******************************************************************************
SYSTEM.SYS_EXPORT_SCHEMA_01に設定されたダンプ・ファイルは次のとおりです:
/home/oracle/dp_dir/expdat.dmp
ジョブ"SYSTEM"."SYS_EXPORT_SCHEMA_01"が日 3月 22 14:19:59 2026 elapsed 0 00:00:28で正常に完了しましたこのダンプファイルはターゲット側にコピーしておく。
Expdp完了後のソースの更新
Replicatできちんと伝搬ができていることを確認するために、ソース側にさらにデータを投入しておく。
insert into test.tab1 values(3, 'POINT B');
commit;
SQL> select * from test.tab1;
COL1 COL2
---------- --------------------------------------------------
1 INITIAL DATA
2 POINT A
3 POINT BReplicatプロセスの追加
「Replicatの追加」ボタンを押下。
「プロセス名」は今回「REP」としている。
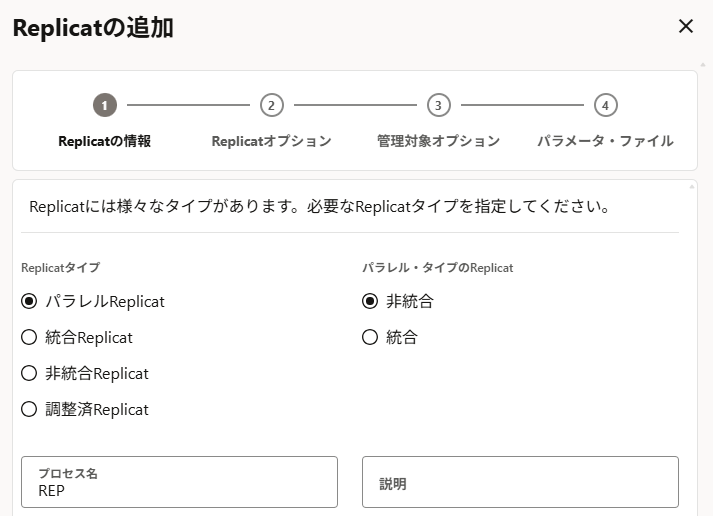
「Replicatトレイル」は Extractの追加時に「Extract証跡」に指定したものと同じ名前を指定する(Hub構成なので)。
「ターゲットの資格証明」には作成済みのものを選択。
「パラメータ・ファイル」には移行対象の表の指定に加えて、「DBOPTIONS ENABLE_INSTANTIATION_FILTERING」を追記する。これはReplicatがインスタンス化CSNの機能を使用して、トレイルファイル内のデータをフィルタすることを許可する設定。
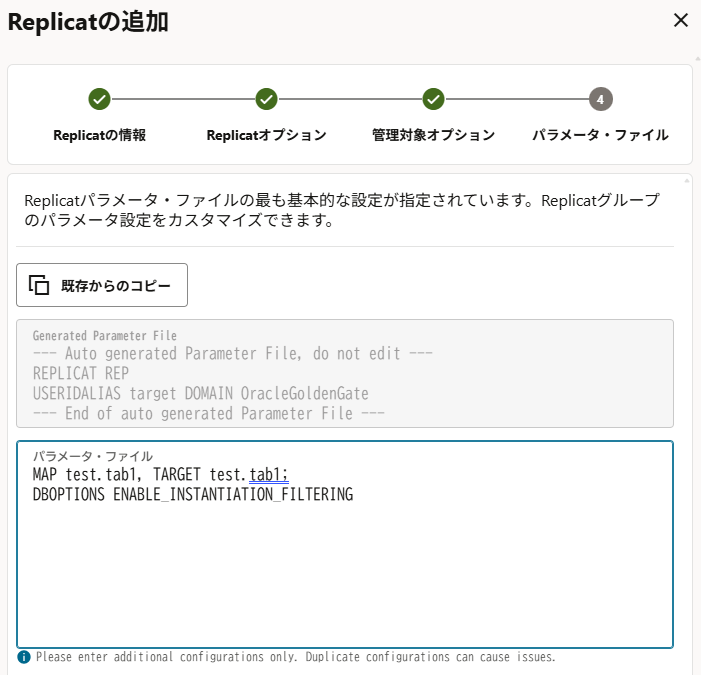
既に初期移行のためのImpdpが済んでいるのであれば、「作成および実行」を押下してReplicatを開始しても構わない。
今回はまだ初期移行が完了していないので、一旦「作成」ボタンを押下してプロセスの作成だけ行う。
初期移行のためのImpdpを実行
ソースで取得したダンプファイルを使って、DataPumpのImpdpを実行する。
[oracle@ol9db26 ~]$ impdp system/oracle@ol9db26.ex.home:1521/orclpdb1 directory=dp_dir schemas=test dumpfile=expdat.dmp
Import: Release 23.26.1.0.0 - Production on 日 3月 22 14:34:39 2026
Version 23.26.1.0.0
Copyright (c) 1982, 2026, Oracle and/or its affiliates. All rights reserved.
接続先: Oracle AI Database 26ai Enterprise Edition Release 23.26.1.0.0 - Production
マスター表"SYSTEM"."SYS_IMPORT_SCHEMA_01"は正常にロード/アンロードされました
SYSTEM."SYS_IMPORT_SCHEMA_01"を起動しています: system/********@ol9db26.ex.home:1521/orclpdb1 directory=dp_dir schemas=test dumpfile=expdat.dmp
オブジェクト型SCHEMA_EXPORT/USERの処理中です
オブジェクト型SCHEMA_EXPORT/SYSTEM_GRANTの処理中です
オブジェクト型SCHEMA_EXPORT/DEFAULT_ROLEの処理中です
オブジェクト型SCHEMA_EXPORT/TABLE/TABLEの処理中です
オブジェクト型SCHEMA_EXPORT/TABLE/TABLE_DATAの処理中です
. . "TEST"."TAB1" 5.5 KB 2行がインポートされました
オブジェクト型SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINTの処理中です
オブジェクト型SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICSの処理中です
オブジェクト型SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICSの処理中です
ジョブ"SYSTEM"."SYS_IMPORT_SCHEMA_01"が日 3月 22 14:35:06 2026 elapsed 0 00:00:24で正常に完了しましたこの時点でSELECTし、Expdp時点のデータがインポートされていることを確認する。
SQL> select * from test.tab1;
COL1 COL2
---------- --------------------------------------------------
1 INITIAL DATA
2 POINT AReplicatプロセスを起動
Replicatの開始ボタンを押下する。
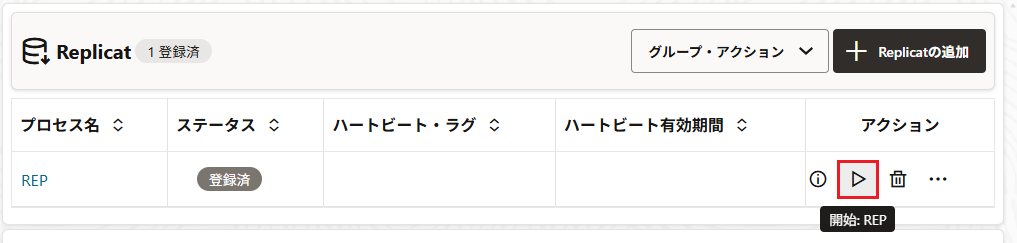
特に問題がなければ、ステータスが実行中に変わる。
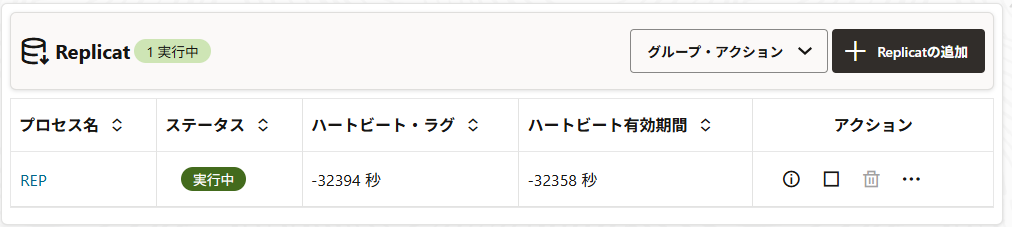
ターゲット側の「Expdp完了後のソースの更新」で投入したデータが適用されていることが確認できれば、無事完了。
SQL> select * from test.tab1;
COL1 COL2
---------- --------------------------------------------------
1 INITIAL DATA
2 POINT A
3 POINT B補足:インスタンス化CSNの利用漏れがあった場合の挙動
今回のケースでReplicatのパラメータに「DBOPTIONS ENABLE_INSTANTIATION_FILTERING」の指定を行わないとどうなるかというと、以下のようにReplicatが一意制約違反でABENDすることになる。
2026-03-22 09:04:37 WARNING OGG-01154 ソース表TEST.TAB1をターゲット表TEST.TAB1にマップするときにSQLエラー1が発生しました。データベース・エラー: OCIエラーORA-00001: 一意制約(TEST.SYS_C008361)に反しています
ヘルプ: https://docs.oracle.com/error-help/db/ora-00001/ (ステータス= 1)、SQL <INSERT /*+ RESTRICT_ALL_REF_CONS */ INTO "TEST"."TAB1" ("COL1","COL2") VALUES (:a0,:a1)>。.
コメント