有効に活用されている場面を見たことがほとんどないこの機能だが、どうやって使うのかを少し調べてみる。
データベースの事前準備
データベースに対して何かしらの処理を実行する必要があるので、前準備としてスキーマとテーブルを作っておく。別に何でもよいのだが、日本郵便が公開している住所の郵便番号情報使うことにした。

上記から utf_ken_all.zip をダウンロードし、utf_ken_all.csv を抽出する。文字コードはUTF8だが改行コードがCR+LFになっているので、これはエディタを使ってLFに変更しておく。
今回データベースには JP というユーザを作成し、KEN_ALL というテーブルを以下のように作る。そして一部の列には索引も作成しておく。
grant dba to jp identified by jp;
conn jp/jp
create table ken_all(
government_code varchar2(15),
zip5 varchar2(15),
zip7 varchar2(21),
prefecture_kana varchar2(4000),
city_kana varchar2(4000),
area_kana varchar2(4000),
prefecture varchar2(4000),
city varchar2(4000),
area varchar2(4000),
op1 number,
op2 number,
op3 number,
op4 number,
op5 number,
op6 number
);
create index ken_all_pref on ken_all(prefecture);Loaderの制御ファイル (control.ctl) を以下のように作る。
LOAD DATA
INFILE 'utf_ken_all.csv'
INTO TABLE ken_all
TRUNCATE
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
TRAILING NULLCOLS
(
government_code char(15),
zip5 char(15),
zip7 char(21),
prefecture_kana char(4000),
city_kana char(4000),
area_kana char(4000),
prefecture char(4000),
city char(4000),
area char(4000),
op1,
op2,
op3,
op4,
op5,
op6
)そして、以下のようにLoaderを実行してCSVをインポートする。
sqlldr userid=jp/jp control=control.ctlデータの投入は終わったので、スキーマレベルで統計情報もとっておく。
exec dbms_stats.gather_schema_stats('JP');Enterprise Manager Cloud Controlの準備
SQLチューニングアドバイザ自体はPL/SQLパッケージプロシージャの実行でも利用できるが、EMCCからの実行方法についても見ておきたかったので事前にEMCC 13cR5に対象のデータベースをターゲット登録しておいた。EMCCはバージョンによってUIが変わってくる場合があるので、今回使用した13.5 RU27 以外では画面構成が異なるかもしれない。
ここまでで、一旦事前準備としては完了。
アドバイザの対象とする処理
SQLチューニングアドバイザがパフォーマンスに問題のあるSQLに対して推奨する内容は以下の通りとされている。
- オブジェクト統計の収集
- 索引の作成
- SQL文のリライト
- SQLプロファイルの作成
- SQL計画ベースラインの作成
このうち、索引の作成とSQLプロファイルの作成については比較的簡単に検証ができたのでその二つを例として結果を記載する。
索引の作成が推奨される例
これは割とわかりやすい例で、索引がなくフルスキャンになってしまうようなケースに対して索引の作成を提示してくれるケース。
今回使用したデータには全国地方公共団体コードが含まれているが、該当するGOVERNMENT_CODE列にはあえて索引を作成していない。where句にこの列に対する条件を指定してSELECTすると、索引がない状態では当然フルスキャンとなる。
SQL> select ZIP7, PREFECTURE, CITY, AREA from ken_all where GOVERNMENT_CODE='20485';
ZIP7 PREFECTURE CITY AREA
--------------------- -------------------- -------------------- --------------------
3999300 長野県 北安曇郡白馬村 以下に掲載がない場合
3999211 長野県 北安曇郡白馬村 神城
3999301 長野県 北安曇郡白馬村 北城
SQL> select * from table(dbms_xplan.display_cursor(sql_id=>'fqj9csgkzfr89', format=>'ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID fqj9csgkzfr89, child number 0
-------------------------------------
select ZIP7, PREFECTURE, CITY, AREA from ken_all where
GOVERNMENT_CODE='20485'
Plan hash value: 2284409065
----------------------------------------------
| Id | Operation | Name | E-Rows |
----------------------------------------------
| 0 | SELECT STATEMENT | | |
|* 1 | TABLE ACCESS FULL| KEN_ALL | 66 |
----------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("GOVERNMENT_CODE"='20485')
Note
-----
- Warning: basic plan statistics not available. These are only collected when:
* hint 'gather_plan_statistics' is used for the statement or
* parameter 'statistics_level' is set to 'ALL', at session or system level
25行が選択されました。このSQLにパフォーマンス上の問題が発生していたと仮定して、SQLチューニングアドバイザを実行してみる。
EMの画面を通してSQLチューニングアドバイザを実行する際は、一旦SQLチューニングセットを作成するか、過去のAWRに存在するSQLを選択するかになるようだ。現実的にはわざわざSQLチューニングセットを作るという方向にはなりにくいんじゃないかと思うが、ここでは問題のSQLを含むSQLチューニングセットを作成するところからやってみる。
SQLチューニングセットの作成
EMでターゲットのデータベースの画面を開き、「パフォーマンス」→「SQL」→「SQLチューニング・セット」を開いたら、「作成」ボタンを押下。
「SQLチューニング・セット名」を適当に設定し次へ進むと、SQL文をどのようにロードするかの選択が出る。
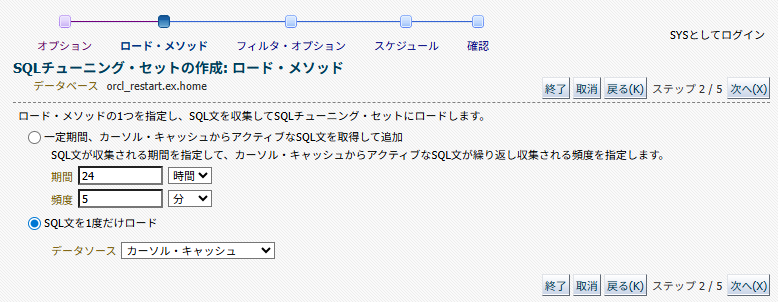
これから実行するSQLをロードする場合は「一定期間、カーソル・キャッシュからアクティブなSQLを取得して追加」を選び、取得対象の期間などを選択する。
今回は、既に実行済みのSQLがすでに共有プール上に存在(カーソル・キャッシュされている)という前提でここからロードすることにする。なお、ここでもAWRからロードするオプションが選べるようだ。
対象のSQLにフィルタが設定できるので、今回はスキーマ名とSQLテキストの一部を条件に指定しておいた。
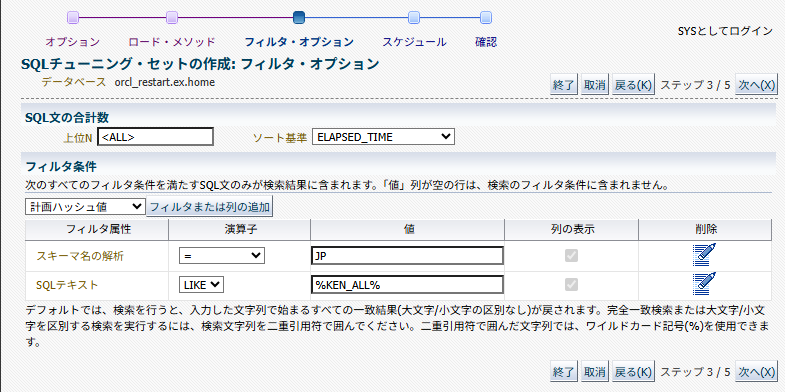
あとは、ジョブを実行すれば指定した条件に該当するSQLを含むSQLチューニングセットが作成される。

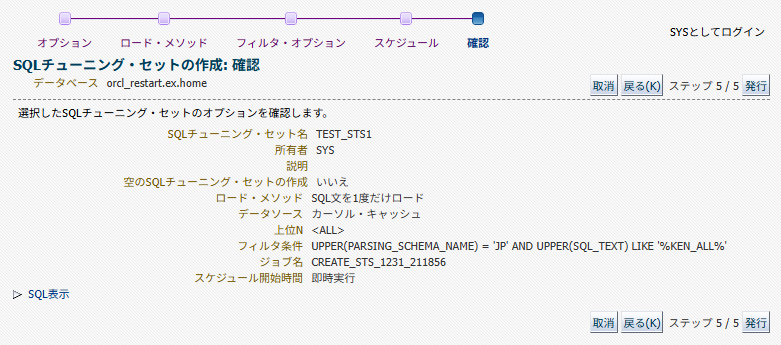
以下は作成されたSQLチューニングセット。不要なSQLが含まれている場合は削除しておく。
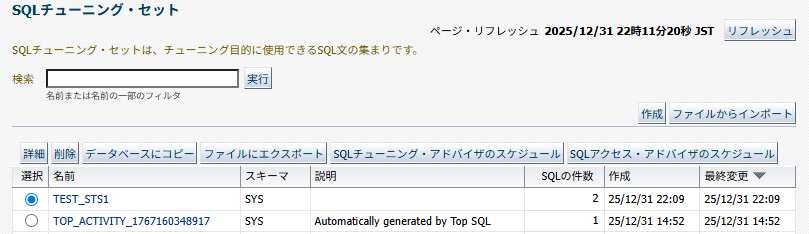
SQLチューニング・アドバイザの実行
SQLチューニングセットの詳細画面から「SQLチューニング・アドバイザのスケジュール」ボタンを押下すれば、すぐにジョブ作成の画面に遷移できる。もしくは、EM画面の「パフォーマンス」→「SQL」→「SQLチューニング・アドバイザ」を開き、「SQLチューニング・セット」の欄に作成済みのSQLチューニングセットを指定すればよい。
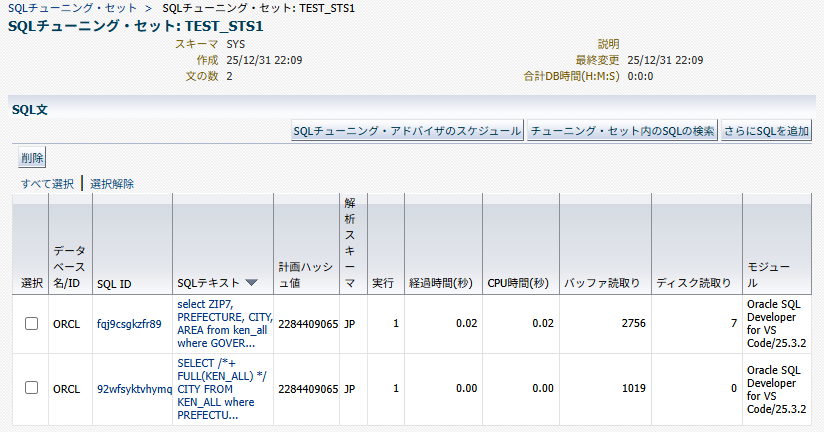
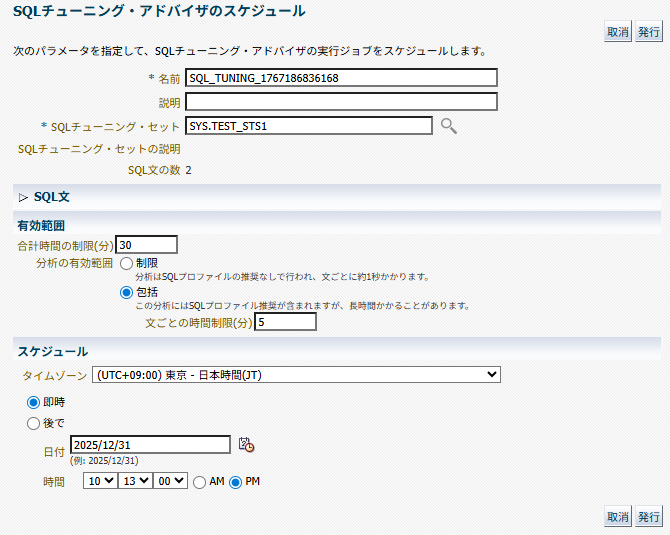
「発行」ボタンを押下してアドバイザを実行する。
EM画面の「パフォーマンス」→ 「アドバイザ・ホーム」画面でアドバイザの実行結果の一覧が確認できるので、そこから実行したSQLチューニングアドバイザのジョブ名を選択する。複数のSQL・複数の推奨事項があるようだと、サマリー画面が以下のように表示される。
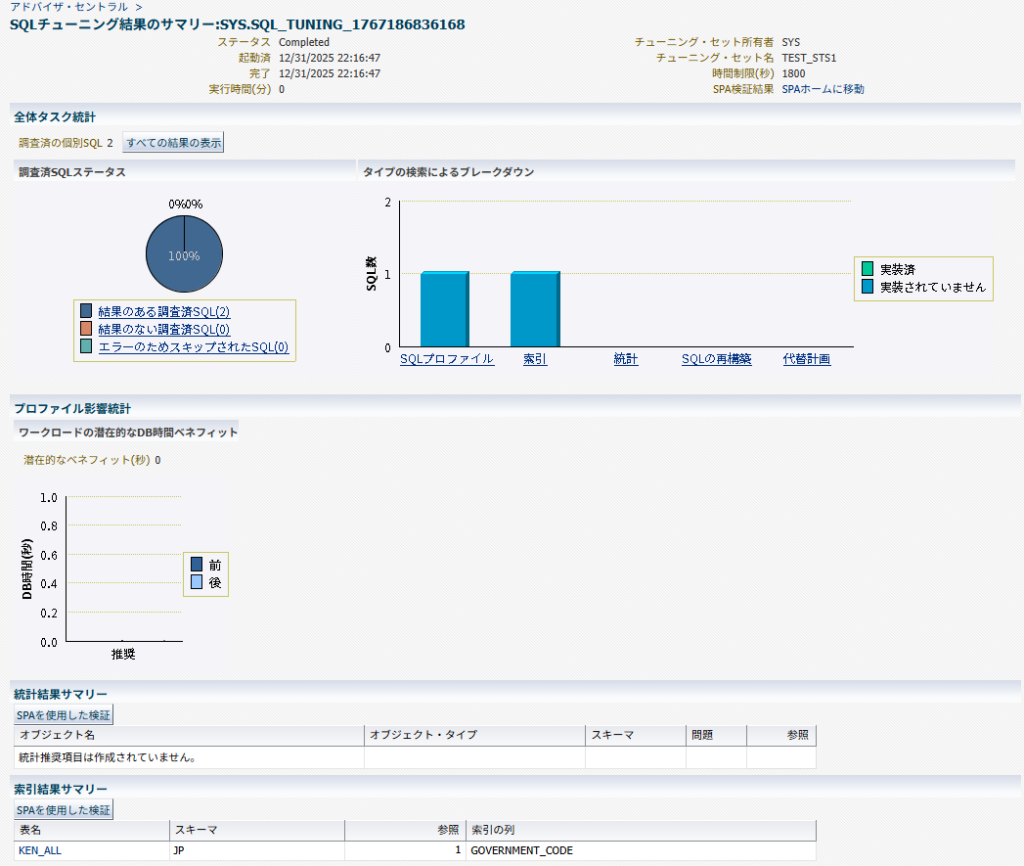
「すべての結果の表示」を押下すると、推奨事項の詳細が一覧表示される。
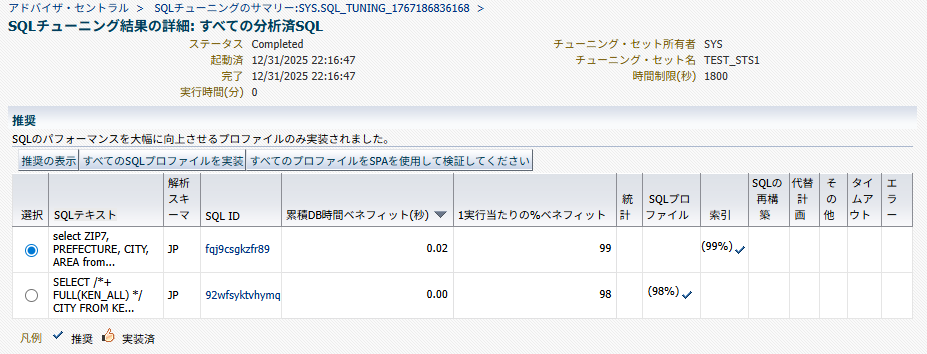
対象のSQLを選択して「推奨の表示」を押下すると、以下のように具体的に推奨される作業が表示される。
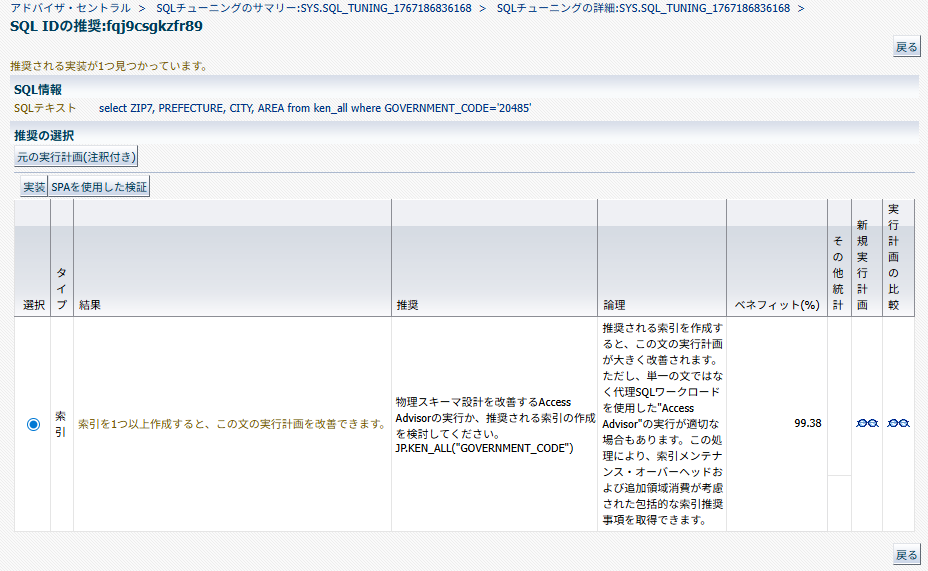
今回は索引の作成が推奨されており、索引の作成前後の実行計画の比較も可能。この場合、フルスキャンのコスト 649に対して索引スキャンではコストが4となっていて、99.38%の改善が見込まれることがわかる。
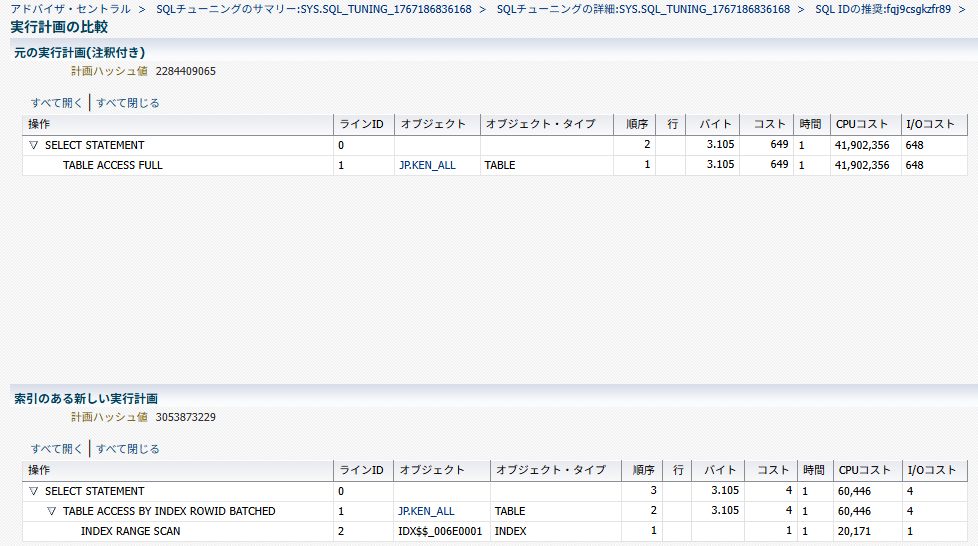
そして、このアドバイザの画面から実際に索引を作成するところまで実行可能。推奨の選択画面にある「実装」ボタンを押すと、そのまま索引作成のジョブ実行画面に遷移する。
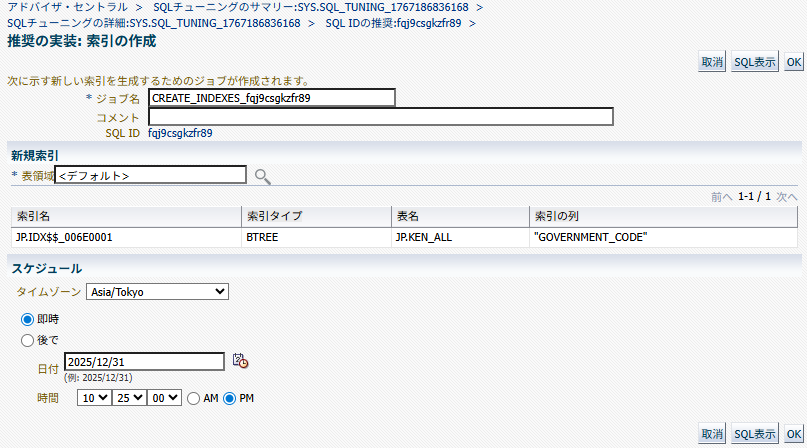
索引名がシステム生成のものになってしまうなど実用上はちょっと問題があるので、「SQLの表示」ボタンを押して確認できるSQLを参考に別途手動で作成するのが適切かと思う。
SQLプロファイルの実装が推奨される例
もう一つ、不適切な実行計画が選択されているようなケースで、SQLプロファイルの実装が推奨される場合がある。
SQLプロファイルはより適切な実行計画を生成するための補助統計情報として利用できるもの。これも実際の運用上で使用している場面は見たことがないのだが、どういう動きなのかを見てみる。テストケースについては、以下の記事を参考にしている。
津島博士のパフォーマンス講座 第38回 SQLチューニングについて | otnjp
具体的なSQLは以下で、索引がある列のSELECTにフルスキャンのヒント句を指定して強制的にフルスキャンとしている。
SQL> SELECT /*+ FULL(KEN_ALL) */ CITY FROM KEN_ALL where PREFECTURE='長野県';
:
SQL> select * from table(dbms_xplan.display_cursor(sql_id=>'92wfsyktvhymq', format=>'ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
SQL_ID 92wfsyktvhymq, child number 0
-------------------------------------
SELECT /*+ FULL(KEN_ALL) */ CITY FROM KEN_ALL where PREFECTURE='長野県'
Plan hash value: 2284409065
----------------------------------------------
| Id | Operation | Name | E-Rows |
----------------------------------------------
| 0 | SELECT STATEMENT | | |
|* 1 | TABLE ACCESS FULL| KEN_ALL | 1712 |
----------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("PREFECTURE"='長野県')
Note
-----
- Warning: basic plan statistics not available. These are only collected when:
* hint 'gather_plan_statistics' is used for the statement or
* parameter 'statistics_level' is set to 'ALL', at session or system level
24行が選択されました。
SQLチューニングセットやSQLチューニングアドバイザの実行は、「索引の作成が推奨される例」のところで一緒に実行しているので割愛する。
この場合、以下のような推奨が表示される。
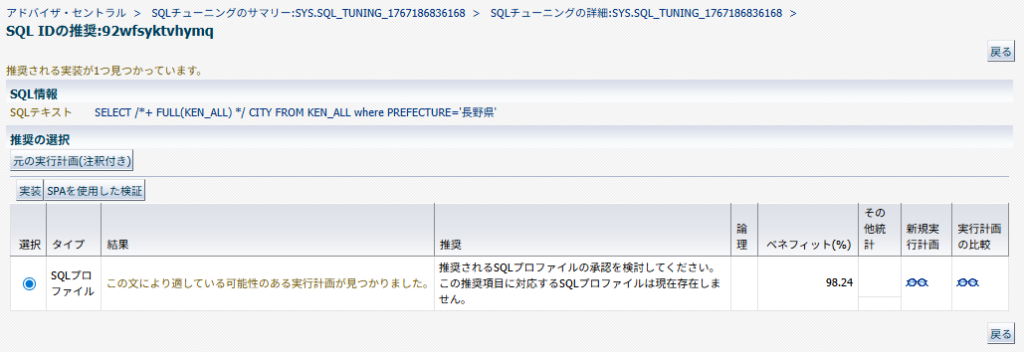
「実行計画の比較」から確認してみると、SQLプロファイルを実装した場合に索引スキャンが選択され、処理時間も大幅に改善することがわかる。
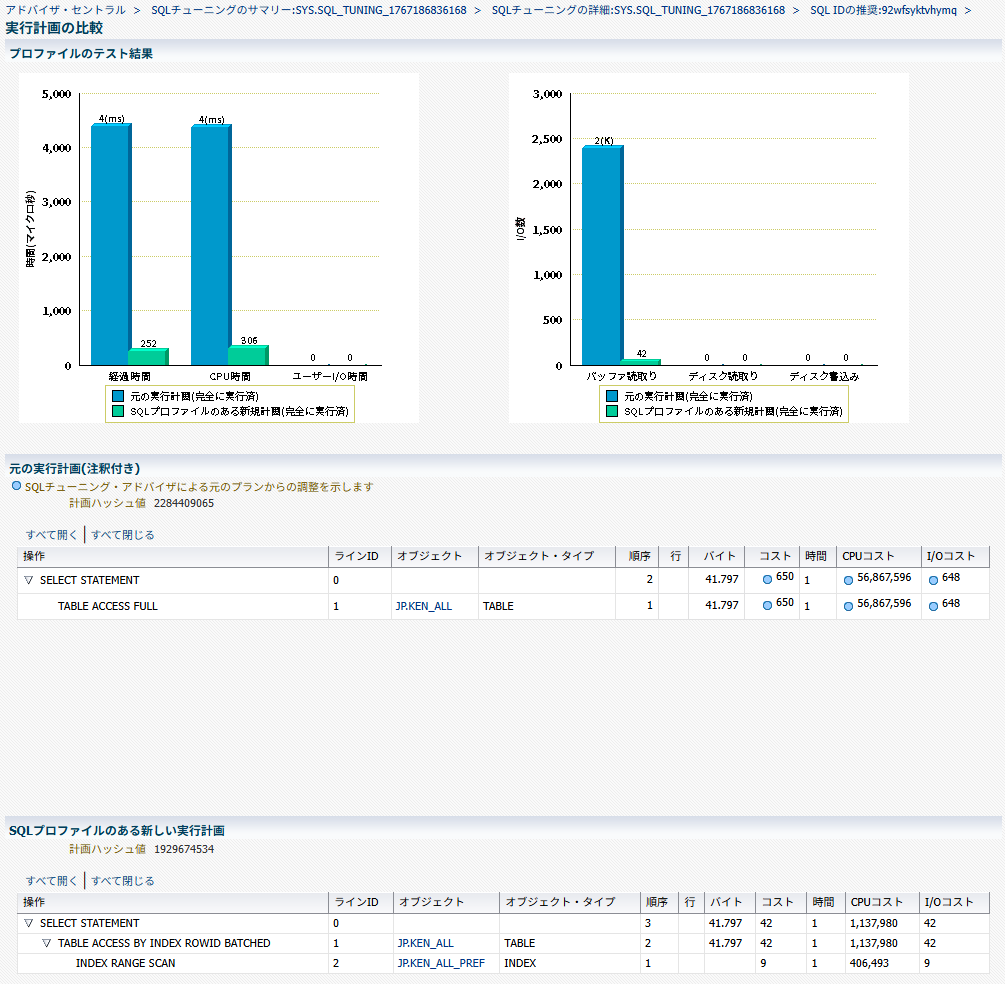
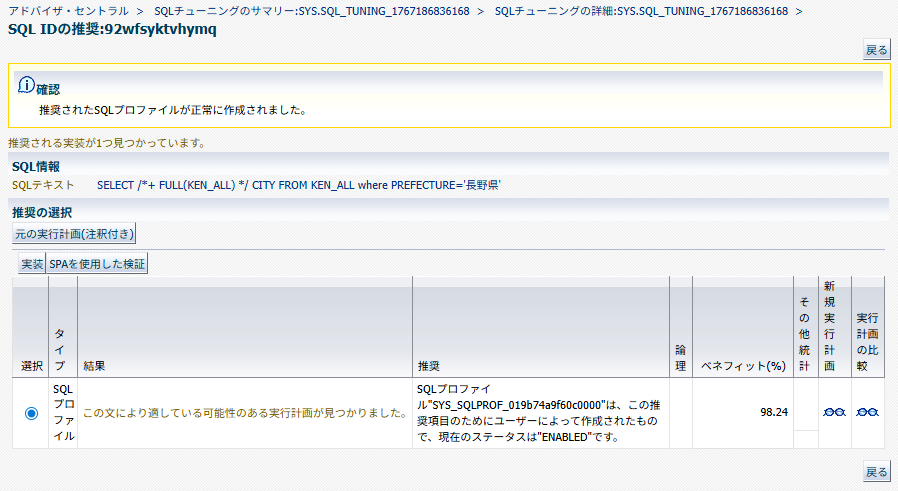
この場合も、推奨の選択画面で「実装」ボタンを押下すればそのままプロファイルの実装が可能。

「パフォーマンス」→「SQL」→「SQL計画管理」画面からも、実装済みのSQLプロファイルの一覧に表示されるようになる(削除する場合はここで可能)。
プロファイル実装後に同じSQLを再度実行してみると、実行計画は確かに索引スキャンに変わる。そして、SQLプロファイルが使われていることもNoteに出力されるようになる。
SQL> select * from table(dbms_xplan.display_cursor(sql_id=>'92wfsyktvhymq', format=>'ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
SQL_ID 92wfsyktvhymq, child number 0
-------------------------------------
SELECT /*+ FULL(KEN_ALL) */ CITY FROM KEN_ALL where PREFECTURE='長野県'
Plan hash value: 1929674534
---------------------------------------------------------------------
| Id | Operation | Name | E-Rows |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| KEN_ALL | 1712 |
|* 2 | INDEX RANGE SCAN | KEN_ALL_PREF | 1712 |
---------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("PREFECTURE"='長野県')
Note
-----
- SQL profile SYS_SQLPROF_019b74a9f60c0000 used for this statement
- Warning: basic plan statistics not available. These are only collected when
:
* hint 'gather_plan_statistics' is used for the statement or
* parameter 'statistics_level' is set to 'ALL', at session or system leve
l
26行が選択されました。ちなみに、SQLプロファイルの実装はあくまでも一時的なものにするべきで、SPMの実施が望ましいとのこと。
[TechNight #91] Oracle Database 最新パフォーマンス分析手法 – Speaker Deck

コメント